Electronic surveillance is spreading around the world, with universities using behavioural data to predict how young people will fare. New research from KU and DTU show, however, that known data as grade point averages are better.
It is becoming increasingly common abroad, especially in the United States, for students to install an app on their smartphone so that universities can monitor the behaviour of young people. The story is that data can reveal the well-being of young people so you can help those who are in danger of leaving the study before time.
However, a Danish study from the University of Copenhagen, DTU and the Copenhagen Center for Social Data Science (SODAS) shows that already known data such as the grade point average in high school are better at predicting the so-called academic performance.
“With simple and less sensitive forms of statistical data, we were able to develop models that were far better at predicting students' performance. It was very surprising for us because the use of big data is growing strongly,” says Andreas Bjerre-Nielsen, assistant professor at the Department of Economics and SODAS at the University of Copenhagen - and is supplemented by Professor Sune Lehmann from DTU Compute and SODAS:
"When you have to predict, as a data scientist, it's tempting to think that you just have to start monitoring all aspects of people's lives as soon as possible. And that the more data you collect, the better your predictions will be. One of the things we point out in the article is that the simple data sources are actually significantly better at predicting student performance than large datasets with information about social networks, GPS patterns, personality tests, etc. So we have to think carefully before we start monitoring the students because it is a major intrusion on people's privacy.”
The researchers believe the Corona pandemic increases the risk of unnecessary data collection right now due to the widespread digital home education.
Simple data versus big data
"So we have to think carefully before we start monitoring the students because it is a major intrusion on people's privacy."
Sune Lehmann, Professor at DTU Compute and Copenhagen Center for Social Data Science (SODAS)
In the study, the researchers used data from their own highly cited Danish data set, Copenhagen Networks Study (CNS). The data set contains behavioural data from 1000 DTU students, and previous studies have just shown that big data about the young people's social networks, attendance, bedtime, etc., can predict how well they will manage their studies.
In the new study, published in the journal PNAS, the researchers have combined data sources from Statistics Denmark (the national Danish institution which collect, compile and publish statistics on the Danish society) in a privacy-safe way with anonymised data sources, and the analyzes have been performed on Statistics Denmark's secure servers.
The researchers have uploaded elements from DTU's data set to Statistics Denmark and the data were locked and anonymized. Next, the researchers paired data on grade point averages in high school with available sociodemographic information about parents' income, parents' educations, and the family's ethnic origin.
In the study, big data with approximately 43 percent accuracy predicts whether a student's exam results will be in the top group of students, in the middle group or at the bottom. It's only slightly better than random guesses, which will hit right in 33 percent of cases.
Conversely, in 58 percent of cases, the model is correct when using simple, accessible data such as grade point averages and social background information. And when you combine big data with register data, the group does not see any predictive improvement over the register data set alone.
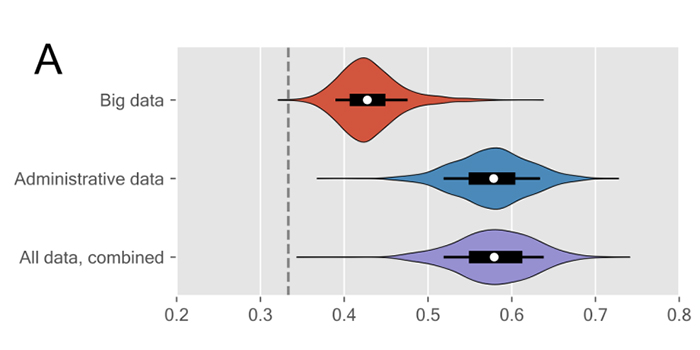
Figure: The graphic shows how precisely the different data sources and the use of advanced algorithms and machine learning can predict how well the students are doing at university. The x-axis shows the balanced accuracy, with the vertical dashed line indicating the baseline of random guessing. “Big data” is all the detailed behavioral data the data scientists had collected from the CNS study. “Administrative data” is the registry data which contains information about past grades as well as sociodemographic information about parents.
Task-specific solution
Sune Lehmann is not really surprised that simple data perform a tooth better than big data. We can compare it to having to solve a specific task:
“If we want to predict how fast an athlete is to run 100 meters, we can look at how fast the runner has run 100 meters in recent times. We can also take the runner to a gym and measure blood pressure and other biometric markers and see how good the runner is for bench press, leg press, etc. These data give a good picture of the person's overall health and fitness, but my guess is that the classic 100 meters time is still a better indicator of how fast the specific athlete can run 100 meters.”
“Similarly, the students' grade point average back in high school says quite a lot about how good they are academically. If we have to predict other things, their average from high school might not be that good. But right up to this specific prediction, the grade point average in high school will be best. So if the choice is between totally monitoring the students around the clock or looking at how they managed the high school, then the right to privacy should count the most,” says Sune Lehmann.